Scaling Law Fails?
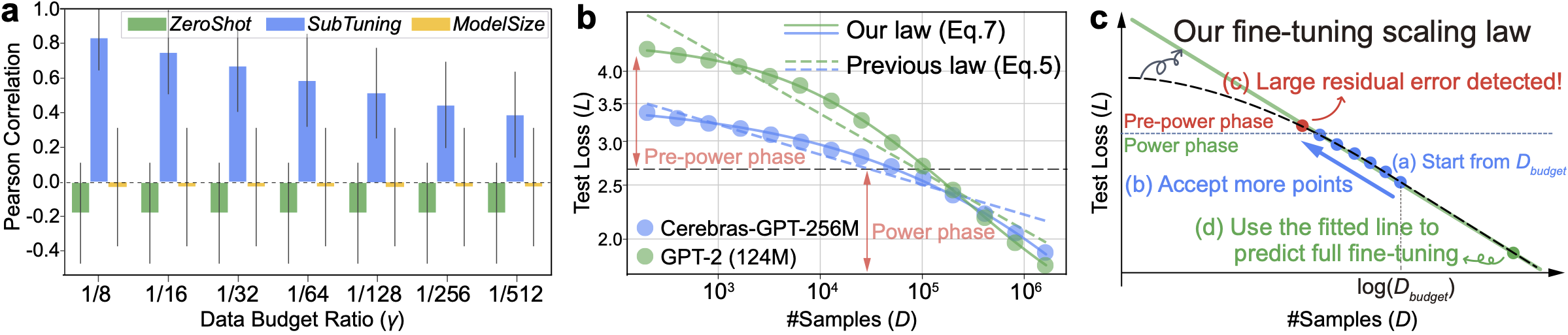
The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with Scaling Law. Unlike pre-training, we find that the fine-tuning scaling curve includes not just the well-known "power phase" but also the previously unobserved "pre-power phase". We also explain why existing Scaling Law fails to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of "pre-learned data size" into our Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection.
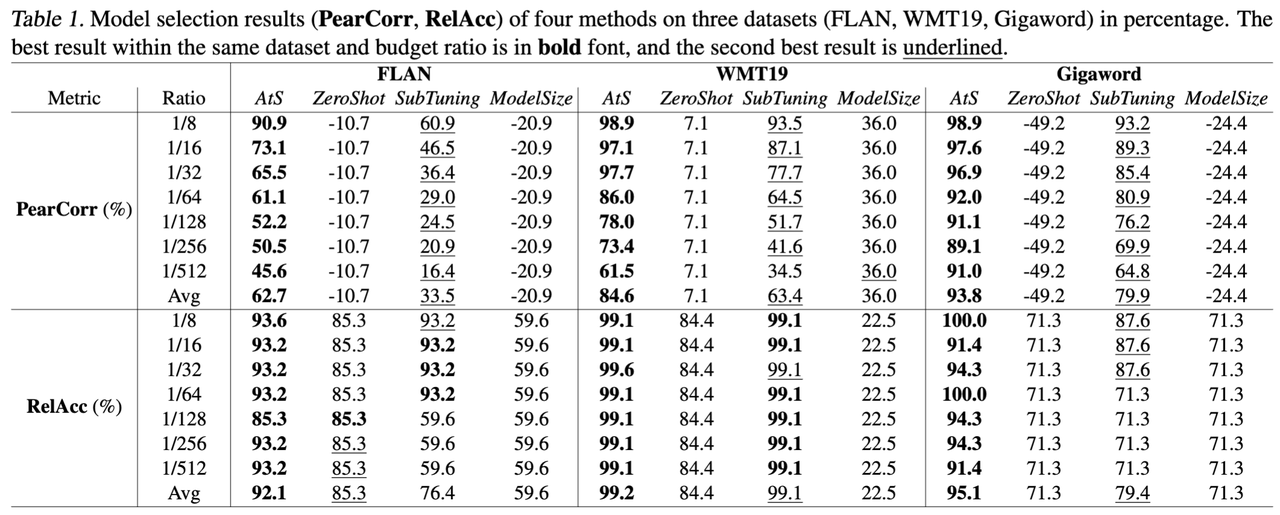
We first formulated the problem of LLM selection and rectified the Scaling Law for fine-tuning senarios. Based on this rectified scaling law, we designed an effective method to address model selection problem.
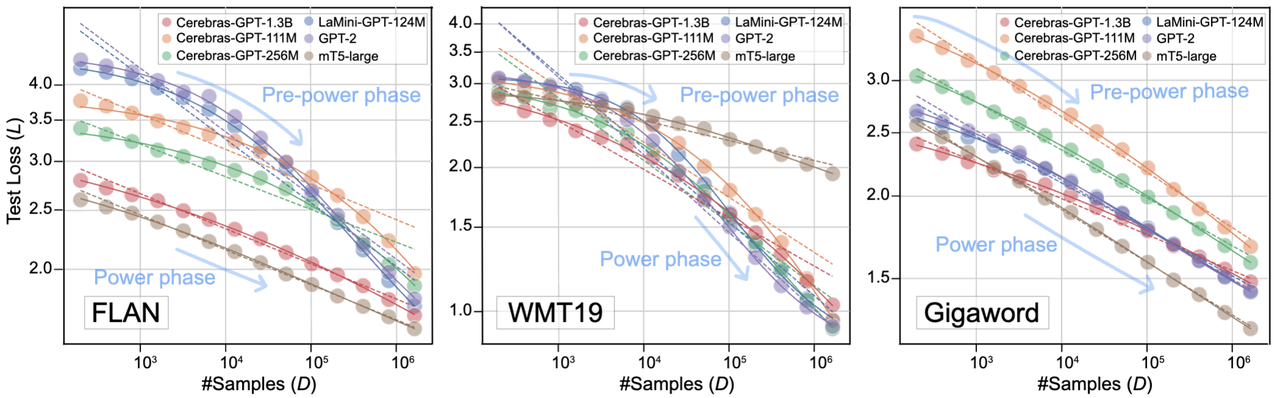
We chose 3 datasets and plotted the phase transition from pre-power phase to power phase, and the fitness of different Scaling Laws. The x and y axes are fine-tuning dataset size D and test loss L in log scale. Each subfigure corresponds to a dataset. Solid lines are the fitting results of our law, and dash lines are the fitting results of vanilla law.
The vanilla scaling law is:
$$ \mathcal{L}(D) = \left(\frac{B}{D^\beta}+E\right)^\alpha. $$
We define the rectified scaling law with dataset size \(D\) for fine-tuning as:$$ \mathcal{L}(D) = \left(\frac{B}{D_l+D^\beta}+E\right)^\alpha. $$
The algorithm is as follows:
@article{lin2024selecting,
author = {Haowei, Lin and Baizhou, Huang and Haotian, Ye and Qinyu, Chen and Zihao, Wang and Sujian, Li and Jianzhu, Ma and Xiaojun, Wan and James, Zou and Yitao, Liang},
title = {Selecting Large Language Model to Fine-tune via Rectified Scaling Law},
journal = {ICML},
year = {2024},
}